I have some questions regarding the content of this article: https://knowledgebase.starwindsoftware. ... correctly/
a) How is the sum of iSCSI connections counted? Only initiator links or really all links (incl. the sync links)?MPIO Policy configuration
We recommend configuring MPIO policy in “Fail Over Only” mode when sum of your iSCSI connections has less the 10GBps throughput.
b) What's the technical reason that you recommend FO if the sum is less then 10Gbit/s?
c) Why FO at all? I only know a few scenarios where FO could be a prefered policy. In most cases it's a waste of bandwidth.
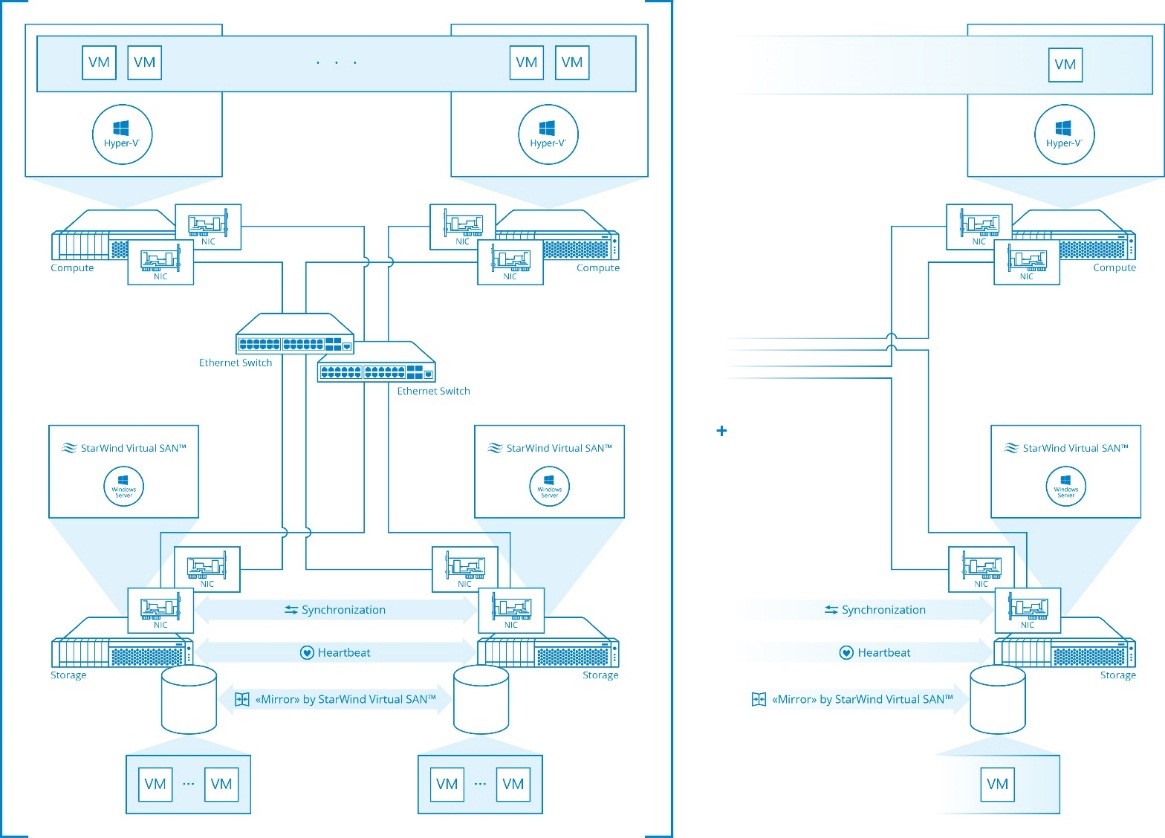
Although I've read some articles about this LB Acc I still don't understand it's purpose. Would you provide a more detailed network plan of a 2 node SAN configuration where it plays a role.Note: MPIO “Fail Over Only” policy can be configured this way only in Hyper-Converged scenario, because it allows to configure local iSCSI connections through loop back IP address (127.0.0.1) which enables Loop Back Accelerator. Loop Back Accelerator allows bypassing TCP/IP stack thus increases transfer performance and decreases transfer latency.
Again, why do you recommend RR here? Like FO in the part above it's usually the worst policy when it comes to efficently saturate MPIO links.If your case does not fit scenario above, we recommend configuring MPIO policy in “Round Robin”, thus setting all iSCSI channels to be continuously active.
Regards
bertram