Futher to my post in Blowfish-IT's thread regarding Starwind consuming large amounts of disk I/O related to reading (little to no write activity) LSFS log files even with no workload, I noticed that the defragmentation levels reported by the console seem quite off (>900%?) and the amount of physical space being consumed is 8-10 times that of the data being stored and has led to the system exhausting the underlying storage and crash.
Example vdisk5 LSFS HA device as seen from node A (highlighted statistics):
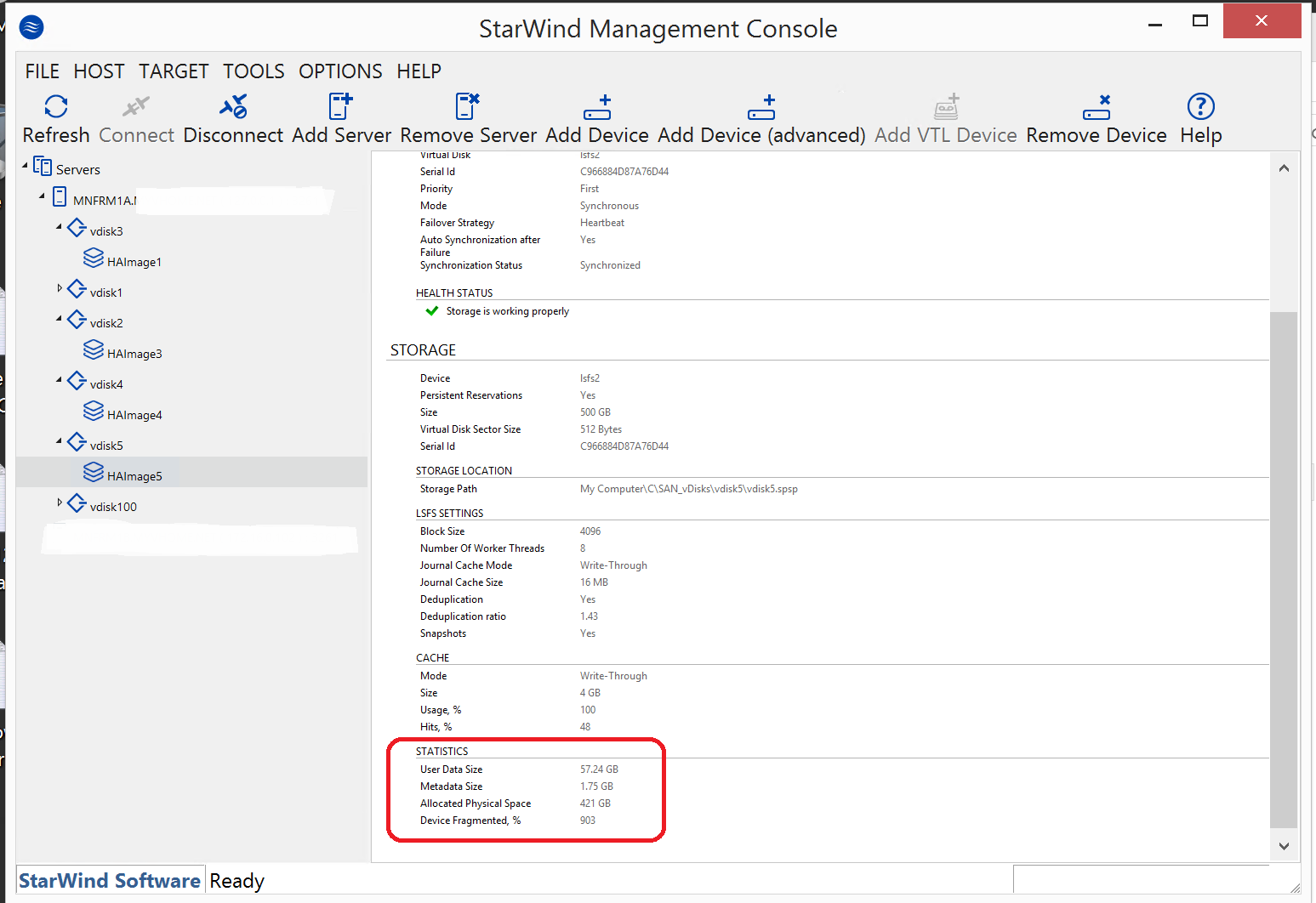
- IMG_0008.PNG (109.79 KiB) Viewed 13803 times
Example vdisk5 LSFS HA device as seen from node B (highlighted statistics):
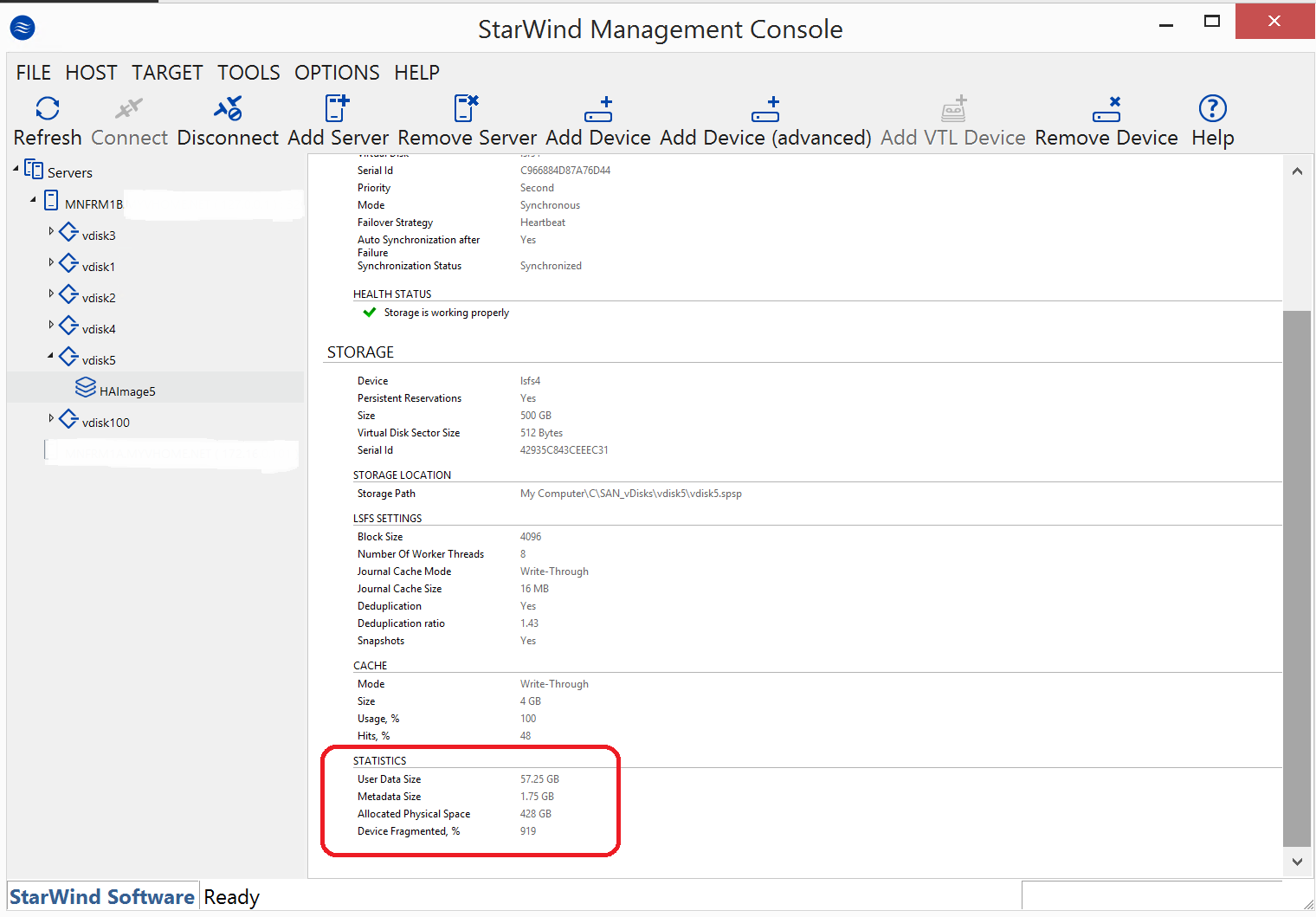
- IMG_0009.PNG (88.91 KiB) Viewed 13803 times
I haven't seen this problem for a few years now, but it seems to have crept back into the latest build (11818)? I noticed that while the Starwind process is running I'm unable to delete any of the lsfs log files for a given device (they're all locked and I would expected this behavior), but if I restart the Starwind service on a node, I can then highlight all of the log files and move them, and only the ones that Starwind seems to care about remain locked and the rest are safely purged - this gets rid of 100's of GB of outdated log files. This same procedure can be repeated for different lsfs devices on different nodes all with the same result; I have to keep repeating this behavior every few weeks to keep the storage consumed under control.
Anyone else seeing this behavior?
Kevin